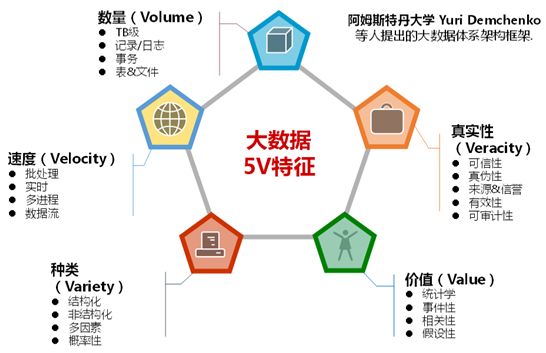
大数据时代
- 数量(Volume),从TB级别跃升到PB级别
- 多样性(Variety),不仅包括传统的格式化数据,还包括来自互联网的网络日志、视频、图片、地理位置信息等
- 速度(Velocity),即处理速度快
- 真实性(Veracity),即追求高质量的数据
关系数据库的瓶颈
| 大数据时代下的系统需求 | 具体表现 | 关系数据库的问题 | 解决方案 |
|---|---|---|---|
| High performance 高并发读写的需求 |
高并发、实时动态获取和更新数据 | 数据库读写压力巨大,硬盘IO无法承受 | Master-Slave,主从分离 分库、分表,缓解写压力,增强读库的可扩展性 |
| Huge Storage 海量数据的高效率存储和访问的需求 |
海量用户信息的高效率实时存储和查询 | 存储记录数量有限,SQL查询效率极低 | 分库、分表,缓解数据增长压力 |
| High Scalability & High Availability 高可扩展性和高可用性的需求 |
需要拥有快速横向扩展能力、提供7*24小时不间断服务 | 横向扩展艰难,无法通过快速增加服务器节点实现,系统升级和维护造成服务不可用 | Master-Slave,增强读库的可扩展性 MMM |
分库分表缺点:
(1)受业务规则影响,需求变动导致分库分表的维护复杂
(2)系统数据访问层代码需要修改Master-Slave缺点
(1)Slave实时性的保障,对于实时性很高的场合可能需要做一些处理
(2)高可用性问题,Master就是那个致命点,容易产生单点故障MMM缺点
本身扩展性差,一次只能一个Master可以写入,只能解决有限数据量下的可用性
NoSQL的优势
NoSQL是Not Only SQL的缩写,而不是Not SQL,它不一定遵循传统数据库的一些基本要求,比如说遵循SQL标准、ACID属性、表结构等等。相比传统数据库,叫它
分布式数据管理系统更贴切,数据存储被简化更灵活,重点被放在了分布式数据管理上。
易扩展
NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展。也无形之间,在架构的层面上带来了可扩展的能力。甚至有多种NoSQL之间的整合。灵活的数据模型
NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个噩梦。高可用
NoSQL在不太影响性能的情况,就可以方便的实现高可用的架构。比如Cassandra,HBase模型,通过复制模型也能实现高可用。大数据量,高性能
NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据库的结构简单。
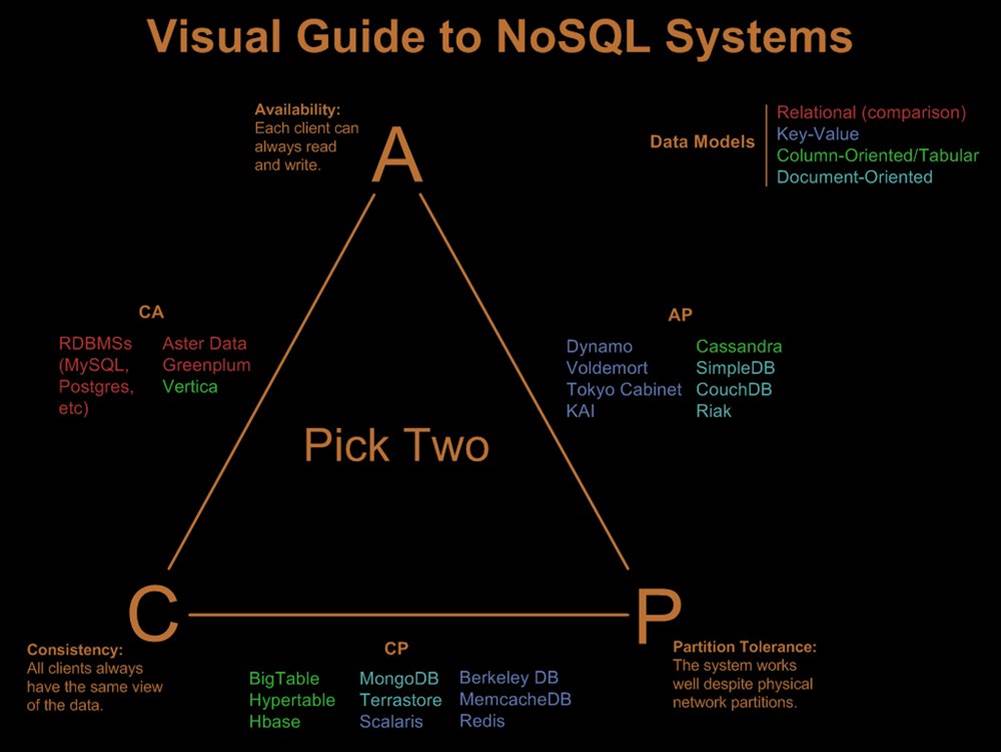
CAP理论
CAP理论是由EricBrewer教授提出的,在设计和部署分布式应用的时候,存在三个核心的系统需求
Consistency 一致性
表示一个事务的操作是不可分割的,要不然这个事务完成,要不然这个事务不完成,不会出现这个事务完成了一半这样的情况。通常情况下在数据库中存在的脏数据就属于数据没有具有一致性的表现。而在分布式系统中,经常出现的一个数据不具有一致性的情况是读写数据时缺乏一致性。比如两个节点数据冗余,第一个节点有一个写操作,数据更新以后没有有效的使得第二个节点更新数据,在读取第二个节点的时候就会出现不一致的问题出现。
传统的ACID数据库是很少存在一致性问题的,因为数据的单点原因,数据的存取又具有良好的事务性,不会出现读写的不一致。
Availability 可用性
好的可用性主要是指系统能够很好的为用户服务,不出现用户操作失败或者访问超时等用户体验不好的情况。可用性通常情况下可用性和分布式数据冗余,负载均衡等有着很大的关联。
Partition Tolerance 分区容错性
分区容错性和扩展性紧密相关。在分布式应用中,可能因为一些分布式的原因导致系统无法正常运转。好的分区容错性要求能够使应用虽然是一个分布式系统,而看上去却好像是在一个可以运转正常的整体。比如现在的分布式系统中有某一个或者几个机器宕掉了,其他剩下的机器还能够正常运转满足系统需求,这样就具有好的分区容错性。
CAP理论的核心:一个分布式系统不可能同时很好的满足三个需求,最多只能同时较好的满足两个。
NoSQL数据模型及分类
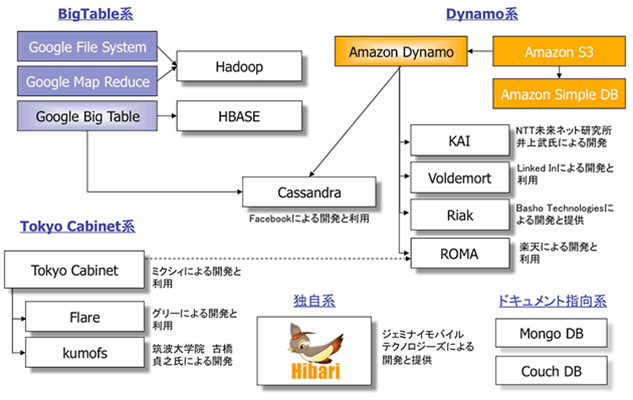
Google的BigTable
BigTable提出了一种很有趣的数据模型,它将各列数据进行排序存储。数据值按范围分布在多台机器,数据更新操作有严格的一致性保证。
Amazon的Dynamo
Dynamo使用的是另外一种分布式模型。Dynamo的模型更简单,它将数据按key进行hash存储。其数据分片模型有比较强的容灾性,因此它实现的是相对松散的弱一致性:最终一致性。
第一种分类方法
| 类型 | 代表 | 特点 |
|---|---|---|
| 列存储 | Hbase Cassandra Hypertable |
按列存储数据的。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有非常大的IO优势 |
| 文档存储 | MongoDB CouchDB |
文档存储一般用类似json的格式存储,存储的内容是文档型的。这样也就有有机会对某些字段建立索引,实现关系数据库的某些功能。 |
| key-value存储 | Tokyo Cabinet / Tyrant Berkeley DB MemcacheDB Redis |
可以通过key快速查询到其value。一般来说,存储不管value的格式,照单全收。(Redis包含了其他功能) |
| 图存储 | Neo4J FlockDB InfoGrid |
图形关系的最佳存储。使用传统关系数据库来解决的话性能低下,而且设计使用不方便 |
| 对象存储 | db4o Versant |
通过类似面向对象语言的语法操作数据库,通过对象的方式存取数据。 |
| xml数据库 | Berkeley DB XML BaseX |
高效的存储XML数据,并支持XML的内部查询语法,比如XQuery,Xpath |
第二种分类方法
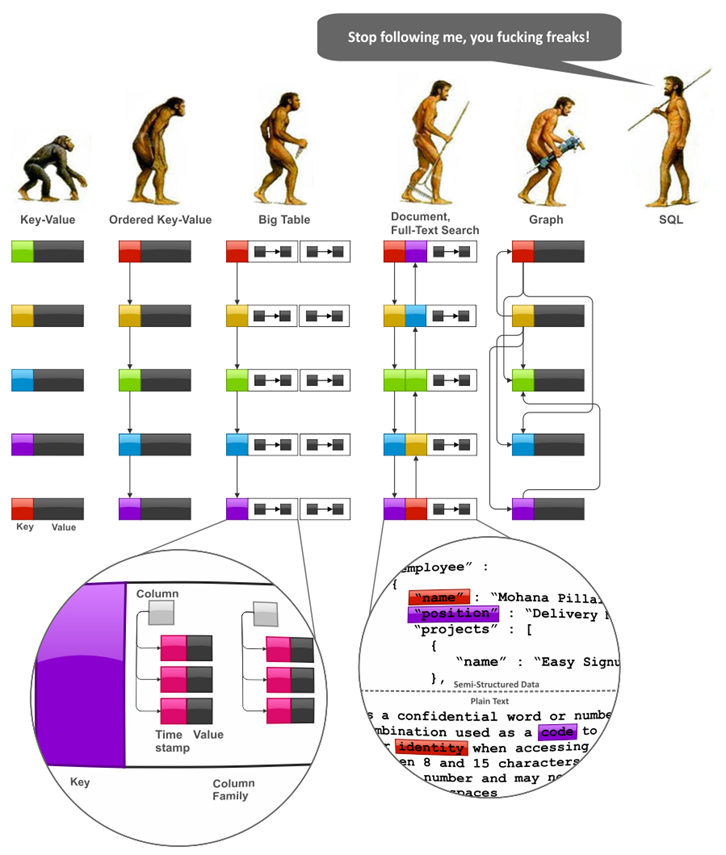
对照上面的图片,我们对几种数据模型进行简单的描述:
- Key-Value模型是最简单,也是使用最方便的数据模型,它支持简单的key对value的键值存储和提取;
- Key-Value模型的一个大问题是它通常是由HashTable实现的,所以无法进行范围查询,所以有序Key-Value模型就出现了,有序Key-Value支持范围查询;
- 虽然有序Key-Value模型能够解决范围查询和问题,但是其Value值依然是无结构的二进制码或纯字符串,通常我们只能在应用层去解析相应的结构。而类BigTable的数据模型,能够支持结构化的数据,包括列、列簇、时间戳以及版本控制等元数据的存储;
- 而文档型存储相对到类BigTable存储又有两个大的提升,一是其Value值支持复杂的结构定义,二是支持数据库索引的定义;4.
- 全文索引模型与文档型存储的主要区别在于文档型存储的索引主要是按照字段名来组织的,而全文索引模型是按字段的具体值来组织的;
- 图数据库模型也可以看作是从Key-Value模型发展出来的一个分支,不同的是它的数据之间有着广泛的关联,并且这种模型支持一些图结构的算法。
重点介绍几个NoSQL
1. BigTable
2. Dynamo
3. Cassandra
4. HBase
5. Redis
6. MongoDB

